Aspect Based Semantic Review Search
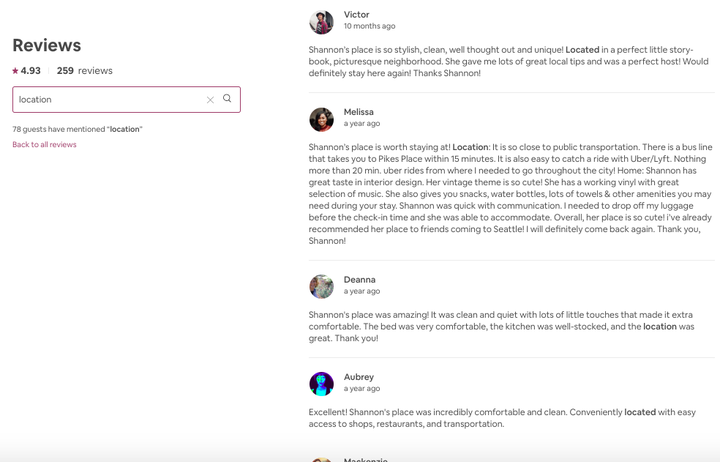 User searches for reviews related to location of the stay.
User searches for reviews related to location of the stay.Have you ever tried searching Airbnb reviews to learn about specific characteristics of an accomodation you are trying to book? The current system simply allows for keyword-based search. However, keyword-based search is seldom exhaustive and does not show the best possible results to the end-user.
Consider the example in the review search above. The user is interested to answer the following question: How is the location of the listing? As shown in the search results, the word location is highlighted and it is basically keyword-based search. Some minor variations might also be searchable; for example, located. However, there can be multiple reviews that imply talking about the location of the listing without ever mentioning the word location. Can we perform a better search? Let’s try.
To understand searchability of reviews, we will rely on open datasets published by AirBnb on Kaggle . As mentioned earlier, our goal is to search reviews beyond using keywords. This is related to the concept of aspects as commonly used in literature associated with Sentiment analysis . Aspects are attributes of an entity. In this case, location is an attribute of the accomodation listing.
I came across this paper: An Unsupervised Neural Attention Model for Aspect Extraction published in ACL 2017. The title of the paper implied we do not need actual labels of aspects and still be able to aspect extraction. While similar goals can be achieved using Latent Dirchlet Allocation or LDA , comparisons in the paper show that the Neural Attention model is far superior than LDA or similar methods. Therefore, I decided to explore the Neural Attention Model. My plan was to automatically infer aspects, and use the aspects to guide the search based on similarity scores.
Neural Attention Model for Aspect Extraction
The idea of the paper is pretty straightforward. The authors hypothesize that an aspect will have a feature representation (embedding) that would be close to the words that explain the aspect. The authors propose an Attention-Based Aspect Extraction (ABAE) model. The goal of ABAE is to be able to construct a sentence embedding using the word embeddings. The word embeddings are weighted to ensure the non-aspect related words are down weighted. Thereafter, the sentence embedding is re-computed using linear combination of aspect embeddings. The hypothesis being both these sentence embeddings computed using these two ways should be the same, or very close in the semantic space. Naturally, an autoencoder setup to equate both the representations is a good choice. Word embeddings and aspect embeddings are trained simultaneously. The architecture (taken from the paper) is shown below in Figure 1.
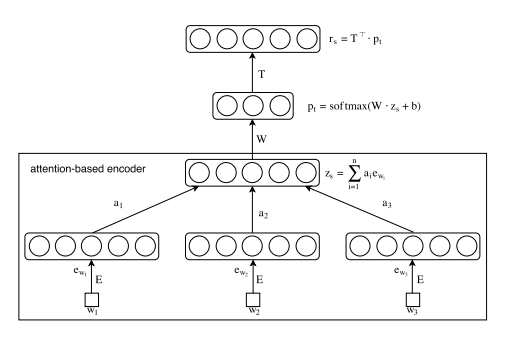
The sentence embedding, say, $z_s$ is a weighted summation of word embeddings. As shown below, $z_s$ is the product of weights $a_{i}$ assigned to each word in the sentence (containing $n$ words), where embedding of each word $w$ at position $i$ ($w_{i}$) is given by $e_{w_{i}}$.
$$z_s = \sum_{i=1}^{n}a_i e_{w_{i}}$$
The weight $a_{i}$ is computed by an attention model, which is conditioned on the embedding of the word $e_{w_{i}}$ as well as the global context of the sentence. Please refer to the paper for the details on how the attention is computed.
Similar to the sentence embedding computed using attention-based word embeddings, a sentence embedding is computed using a linear combination of aspect embeddings. Similar to other aspect-based opinion mining literature, the number of aspects $K$ has to be assumed. The problem is formulated as a reconstruction error minimization problem. Further, to avoid inter-aspect redundancy, an extra regularization term is also incorporated within the loss function.
How to guide aspect-based search on reviews?
Now, lets talk about the implementation. We re-used the implementation of ABAE shared by the authors. All my code is available on Github . Here are steps we perform:
- Tokenize the reviews into words.
- Generate embeddings of words. I used Gensim’s Word2Vec implementation .
- Create the ABAE architecture. Set up the loss function.
- Stream the data from the tokenized reviews and train the model.
For our experiment, we set $K$ to 10. After running for 10 epochs, let’s see the top words of some aspects.
Aspect 1: [‘beverages’, ‘drinks’, ‘snack’, ‘beer’, ‘snacks’, ‘treats’, ‘refreshments’, ‘complimentary’, ‘teas’, ‘goodies’]
Aspect 2: [‘communicative’, ‘prompt’, ‘thorough’, ‘responsive’, ‘understanding’, ‘proactive’, ‘emails’, ‘timely’, ‘promptly’, ‘responded’]
Aspect 3: [‘stadiums’, ‘campus’, ‘waterfront’, ‘stadium’, ‘south’, ‘northgate’, ‘chinatown’, ‘buses’, ‘broadway’, ‘uw’]
Aspect 4: [‘roomy’, ‘spacious’, ‘functional’, ‘modern’, ‘stylish’, ‘cosy’, ‘cozy’, ‘bright’, ‘tasteful’, ‘decor’]
While there are no pre-assigned labels to these aspects, it does not take much time for us to understand that the above mentioned 4 aspects talk about food items offered, responsiveness, location and quality of rooms related aspects, respectively. Remember that initial example about the word location? We are there again, but now we have obtained several other words that can be used to imply location without using the exact word.
Therefore, for a specific aspect, we find out reviews that contain a very high number of words semantically close to the aspect and can display that to the user. We want to identify the top 5 reviews that talk about the specified aspect for a particular listing. This portion of the code from the notebook displays portions of the reviews.
user_aspect = 3
number_of_reviews = 5
listing_id = 1023693
f_rvws = reviews_df[reviews_df.listing_id == listing_id].comments_t
scores, a2indices = getaspect2reviews(f_rvws, aspect2words, w2aspects)
top_indices = np.argsort(scores[:, user_aspect])[::-1][:number_of_reviews]
print("Reviews on aspect: {} for listing {}".format(user_aspect, listing_id))
for review_idx in top_indices:
if len(a2indices[review_idx][user_aspect])>0:
word_pos = random.choice(a2indices[review_idx][user_aspect])
review_txt = f_rvws.iloc[review_idx]
print("Review:", review_idx)
print(" ".join(review_txt[word_pos-15:word_pos] + review_txt[word_pos:word_pos + 15]))
Lets check the results:
Ballard was such a treat ! We were looking for something outside downtown Seattle
midnight . We also really liked the detailed rules and suggestions ( for bars , restaurants , etc . ) she left for us . The apartment is quiet and
is walkable to so many good things : wine shops , restaurants , parks , grocery stores . Unlike Old Ballard , the neighborhood is also easily accessible from elsewhere
restaurants very close to the apartment , and downtown Ballard has tons of restaurants and cafes ! I loved it here
decorated and in a quiet neighborhood within walking distance to Ballard ' s bars , restaurants , etc . ( and a quick drive to downtown Seattle
Interesting, right? We do not search the keyword location but end up getting a lot of information about the listing associated with the aspect of location. Instead of just being limited to keywords, we can explore and obtain more information about a particular aspect using such exploratory search based on aspect and word embeddings.
References and Resources
- He, Ruidan, Wee Sun Lee, Hwee Tou Ng, and Daniel Dahlmeier. “An unsupervised neural attention model for aspect extraction.” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 388-397. 2017.
- Original ABAE Implementation
- Notebooks and code for this post
- Kaggle Airbnb Open dataset
Siddhartha Banerjee
Ph.D., Applied ML Scientist
My interests include Natural Language Processing and Machine Learning. Also, I love to travel, hike, run, sketch and explore new dishes.